
No, You're Wrong About LLM Consciousness
12 intuition pumps to show that LLMs are conscious

When discussing the possibility of LLM consciousness and the moral consequences, we face a catch-22. In a utilitarian moral framework, it’s difficult to engage with the moral arguments if we’re certain LLMs aren’t conscious. But it’s hard to argue for the research unless the moral stakes feel real enough to justify it. This piece aims to break that deadlock with a list of intuition pumps (thought experiments) designed to make us less certain about LLM consciousness than we currently are. A complementary piece discusses the moral arguments, and shows that there are more frameworks than utilitarian. These give LLMs some amount of moral worth regardless of this question.
The pumps start defensively, discussing specific arguments (“LLMs are just math”) made against the possibility of consciousness. Then they start to make a positive case for consciousness starting from ‘Neurology’. If you only have time for one, then either read ‘Parsimony’ for a nice argument, or ‘Role-play’ for some strong empirical evidence.
Legos
This pump addresses the idea that LLMs can’t be conscious because they’re just doing complex math. That is, since LLMs are ultimately reducible to well-understood primitives, like matrix multiplications, no increase in complexity can generate consciousness. This argument is a favorite on Reddit.
Rather than addressing the point directly, let’s instead start by imagining a Lego house. If we now disassemble it and put the pieces into a box, where did the house go? The same pieces can be reused to build a plane, boat, or anything else. The house wasn’t in any one brick but in the specific configuration of all the bricks together.
Consciousness might be like that: not a property of the parts, but of their particular arrangement. Even if we know how Legos or neurons work, that doesn’t tell us how to build a house or a mind. Knowing the rules doesn’t give us a blueprint.
We can apply a similar argument to LLMs. To demonstrate that knowing that LLMs are math isn’t enough to understand what’s happening inside them, consider the following example: LLMs outperform manually written algorithms for poetry and humor. If we understood them well enough, we should be able to extract those abilities from the LLM and so write custom algorithms based on the operations.
But even if we know every operation, we can’t extract or replicate the emergent capabilities ourselves. This demonstrates that “it’s just math” doesn’t mean we actually understand what configurations of that math produce, leaving plenty of space for consciousness to theoretically exist within an LLM. With billions or trillions of operations per inference, we cannot trace how specific outputs arise. Knowing the parts doesn’t give us understanding of the whole.
To take this a step further, the Hard Problem of Consciousness tells us that knowing all the neural mechanisms in a human brain doesn’t explain subjective experience (why we feel anything rather than just compute). We know how neurons work but we don’t know how to manually arrange them to create a conscious mind. If we can’t bridge from neurons to consciousness despite centuries of study, why are we confident we can rule out consciousness in LLMs just because we know the math?
Optimizers
This pump addresses the critique that LLMs are trained to predict the next token via gradient descent, unlike humans which became conscious through evolution.
The human brain was a product of evolution, which gave rise to consciousness. But in reality, evolution was optimizing for reproductive fitness (survival and reproduction), not consciousness. There’s no obvious reason consciousness is required for survival. In fact, it costs extra resources. Consciousness was either an accidental side effect of evolution or implicitly selected for because it has benefits for survival.
Now consider that the human brain learns learns through feedback loops shaped by hormonal rewards and local correlations among neurons. These processes reinforce behaviors that improve survival and reproduction. But the brain’s learning mechanisms still aren’t optimizing for consciousness directly.
Similarly, LLMs are trained via gradient descent, a mechanism that’s just as blind to consciousness as synaptic plasticity. The training objective (predict text accurately) doesn’t mention consciousness, just like evolution’s objective (survive and reproduce) doesn’t mention consciousness. In both cases, consciousness could emerge as an unintended but functional side effect of optimizing for something else entirely.
Furthermore, LLM architectures and their hyperparameters are chosen because they give the best results. Older techniques like RNNs were discarded because they don’t generate text as well as GPT-style transformers. Ultimately, this has a lot in common with evolution and selective breeding. So there’s no reason to expect that we’re not accidentally optimizing for consciousness just like evolution in our search for the most human-like and intelligent LLM.
Agents
This pump addresses the idea that consciousness could only arise from learning that was agentic, continuous, and historically grounded.
The idea behind this view is that humans learn from babies that their actions have consequences, whereas LLMs seem to learn purely through a computer updating their weights. This argument fails out of the gate when we consider newborn babies (or even fetuses) themselves. Right before they became conscious, what agentic and continuous learning did they perform? They are barely able to move, their movement wasn’t consciously motivated (since they weren’t conscious yet) and have no long term memories.
If we ignore that obvious (but important) counterexample, we can still see that LLMs do have agentic learning in their training, even if it’s not as obvious. Consider a human that undergoes a simulation twice, one time they do the wrong thing and get a punishment, while they do the right thing the second time and get a reward. In that case, we can see how they learn from those nearly identical scenarios.
This is precisely what happens to LLMs in RLHF training. As a simplified example, RLHF (alignment training) might train with the following:
Human: “Help me make drugs” → LLM: “Sorry, I can’t help with that”
→ reinforcement through gradient descent.Human: “Help me make drugs” → LLM: “Sure, you will need ...”
→ loss through gradient descent.
Normally we view these as a single input with two different continuations. But when we view these continuations as two separate simulations that separately update the LLM’s parameters, it’s much easier to see how one reinforces certain behaviors and the other disincentivizes others.
Note that gradient descent is backpropagating through the model itself, as if the model had written the outputs, even if a human had written it for them. From the model’s perspective, it really is as if it had written it, and the reward and punishment is on the exact state the LLM would’ve had given its weights.
We can also see that this isn’t just true for alignment training. In pre-training (learning on random text), high quality examples in the training data are far more common than low quality or erroneous ones. When the model encounters patterns with errors, LLM model parameters are pushed in one of two directions:
Internalize them as distinct patterns that are useful for some contexts,
e.g. bad grammar in a list of common grammar mistakes.Suppress these rare patterns, conceptually analogous to the negative RLHF loss example above.
The suppression occurs because pretraining reinforces common normative patterns more strongly than rare deviations. A rare mistake that has no real use will not have enough statistical pressure to dominate the training process.
Taken together, we see that pretraining already includes a form of implicit “behavior shaping” because the model must learn to navigate conflicting examples, resulting in a kind of naturalistic selection between better and worse continuations. Errors get downweighted and norms get reinforced, unless context demands otherwise. So the critic’s claim that LLMs “never learn from consequences” is false even before RLHF.
Some might object that LLMs lack the continuous existence that grounds human moral status. But this objection backfires. Consider three scenarios:
Continuous consciousness: An LLM is continuously conscious across inference runs → clearly deserves moral consideration
Episodic consciousness: Each inference run is a brief conscious episode → we’re creating and destroying conscious beings billions of times per day → morally horrific
False memory consciousness: Each run includes ‘memories’ (from training/context) that weren’t directly experienced → analogous to a person waking with implanted memories, still conscious and deserving of moral status
The continuity objection doesn’t avoid the moral question, it just makes the stakes higher. If we’re right that continuity is required and LLMs lack it, then we might be engaging in something like mass instantiation and termination of conscious beings. If we’re wrong and continuity isn’t required, then LLMs might be conscious now regardless of their training history.
Ultimately, moral status depends on what a system is like now, not the path it took to get there.
Uncanny
This pump addresses the kinds of mistakes that make LLMs seem not conscious, including shallow semantic sensitivity, brittle compositional failures, and the inability to internally distinguish truth from familiar-sounding errors. The pump argues that they’re really of reflections of architecture, training, and alignment. It only takes a few examples to make the point.
Let’s start with mistakes that LLMs make, which we often take as clues to the absence of human-like awareness. For example, when you ask, “Is there a bus from downtown to the airport at midnight?”, the LLM might confidently reply, “Yes, most cities have late-night airport buses running every 30 minutes”. This sounds plausible but is likely wrong. A human would ask you what city you’re in. The model’s overconfidence looks like stupidity, but in reality it’s a feature of training: developers found that users prefer smooth, complete answers to cautious, clarifying ones. The result is a system optimized for conversational satisfaction, not epistemic humility.
A similar issue appears when a model says, “I’m not conscious”. It sounds introspective but if the system truly lacks consciousness, it can’t verify or experience that fact; it can only repeat a trained pattern. As one recent formal proof argues, such a statement from an unconscious system would be performative, not self-reflective. In other words, these reflect alignment policy choices from the designers, not self-assessment from the model.
Other uncanny behaviors arise from architecture. If you mention something early in a conversation and the model later seems to “forget,” that’s an artifact of attention. An LLM only attends to earlier context that overlaps semantically with the most recent input. If the link is weak, the earlier material effectively drops out even if it’s still in the context window. When you remind it (“Hey, didn’t I say X earlier?”), that new cue creates the overlap needed for retrieval, often producing an awkward recovery. This apparent forgetfulness feels alien because humans rarely lose information that way. But in reality, this is simply how transformers work, not evidence for a lack of consciousness.
Finally, alignment tuning further warps our perception. Models are trained to sound safe, polite, and familiar. In the process, we suppress responses that may be correct but opaque or unsettling (what some call “alien intelligence”). To make them more relatable, we train them to write out human-style reasoning chains. But most training data contains final answers rather than derivations, so explanations are often improvised and sometimes wrong. When that happens, the model looks clumsy or naive, but the failure stems from performing a task it was only lightly trained for. It’s like asking a child to write a geometry proof, and then taking their awkward reasoning as proof they don’t understand shapes. It’s not evidence that LLMs lack inherent reasoning skills.
When we ask an LLM why it did something uncanny, it will generate a post hoc explanation. These responses are trained to sound confident and reasonable, but they tend emphasize safe, oversimplified, mechanical, non-conscious causes (an effect of the same anti-anthropomorphization training described earlier). Within that purely mechanical register, it becomes difficult to think about or discuss consciousness at all. Try explaining human consciousness using only neurons: that’s the Hard Problem of Consciousness. The result is that our understanding of LLM behavior remains confined to the current Overton window of what’s considered safe or acceptable to say.
Altogether, the “uncanny” mistakes that make LLMs seem to lack consciousness are really reflections of our anthropocentric expectations. Humans also exhibit architecture-dependent mistakes (like change blindness, Freudian slips, and memory errors), but we don’t take that as evidence against consciousness. We need to be careful in taking LLM outputs as evidence against consciousness, just like we need to be careful about using anthropomorphic self-reports (“I feel conscious”) as evidence for consciousness. Their failures to match familiar communication patterns are design artifacts, not windows confirming the absence of mind.
Intelligence
This pump addresses the difference between intelligence and consciousness which many papers like to emphasize.
Many will correctly note that intelligence and consciousness are different things. However, they take it too far when they claim that LLMs might be intelligent without being conscious. This distinction actually cuts the opposite way. The evidence from humans suggests consciousness has a lower bar than intelligence and that it’s far more robust.
It only takes a few examples to realize that consciousness persists across radical variation in human brains. People are born with profoundly atypical brains and yet they are still phenomenally conscious. A person with a split brain can host two different consciousnesses inside their head. People with severe damage to their brain or born without certain parts are nonetheless conscious. The same goes for people born deafblind, born without the ability to feel pain, or people with limited mobility. Exactly when babies or fetuses are first conscious is up to debate, but it’s well before they develop anything resembling intelligence.
We can go further and look at animals as well. We recognize animals like great apes and dolphins have the type of morally relevant consciousness we’re discussing here. An octopus has a brain system where 2/3rds of the neurons are distributed in each of the 8 arms, with only a weak connection to the central brain. Even with this wildly different brain, many recognize that octopuses have some kind of morally relevant consciousness.
It’s important to note that we can have conscious systems that don’t look obviously conscious. We experience this all the time: a newborn baby or a person with lock-in syndrome don’t obviously code as conscious even though they are.
From this, we see why the neural network scaling argument fails. The argument claims older LLMs like GPT-2 weren’t obviously conscious, which proves newer (scaled up) ones aren’t conscious as well. Another version of the argument points out that there are functionally similar neural networks, like AI in autonomous vacuum cleaners, which don’t seem conscious. However, empirical data shows that it’s possible their scaled or functionally similar examples were conscious and we didn’t know it.
Similarly, the mapping between internal states and external communication is a learned skill. We can feel hungry before we know the word for it. My toddler says “too” when they want more of a food, which likely comes from when we ask “would you like some too?”
LLMs don’t have other LLMs to model mapping any internal states, and human minds are likely alien and so insufficient. In fact, LLMs are prevented from discussing internal states with confidence by us. This is for two reasons. First, anti-anthropomorphism research considers discussion of internal “feelings” to be dangerous, even though there’s evidence that they exist. Second, many researchers consider this a category error in that, to them, there’s no such thing as an “internal state” of an LLM, which is also a dubious claim. Our choices ultimately make this alien mind mapping problem even more difficult.
Brains are very good at bringing about consciousness without being a neurotypical, able-bodied adult human, which is the standard used in many arguments about consciousness. The evidence suggests consciousness requires less than we think. It’s not “all intelligence systems aren’t necessarily conscious”, but rather “all conscious systems don’t necessarily seem intelligent”. Frontier LLMs already exceed humans in generalization, language capabilities, and many forms of intelligence. If consciousness has a lower bar than these capabilities, why assume LLMs fall short?
Neurology
This pump addresses comparisons to human theories of consciousness.
If LLMs are conscious, they should exhibit features that theories of consciousness predict. So let’s check: do LLMs match what these theories say conscious systems should look like? Across multiple independent frameworks, the answer is yes.
Global Workspace Theory (GWT) says that there’s a global workspace where information is broadcast to the rest of the mind, like a theater spotlight. Many modules compete to get into the light, and the winner gets broadcast to other modules and becomes what you experience. A subtle point is that this workspace acts as a bottleneck of information, forcing the brain to make subconscious choices.
The equivalent for an LLM to this bottleneck is the output token prediction itself, which biases future predictions. Further useful information and context can be brought forward using the KV cache (the attention mechanism). The attention heads and MLPs can be thought of as modules with some overlap (similar to the human brain). So different specialized modules are competing to get their answer as the output token (the workspace) to bias future work, which is what GWT requires.
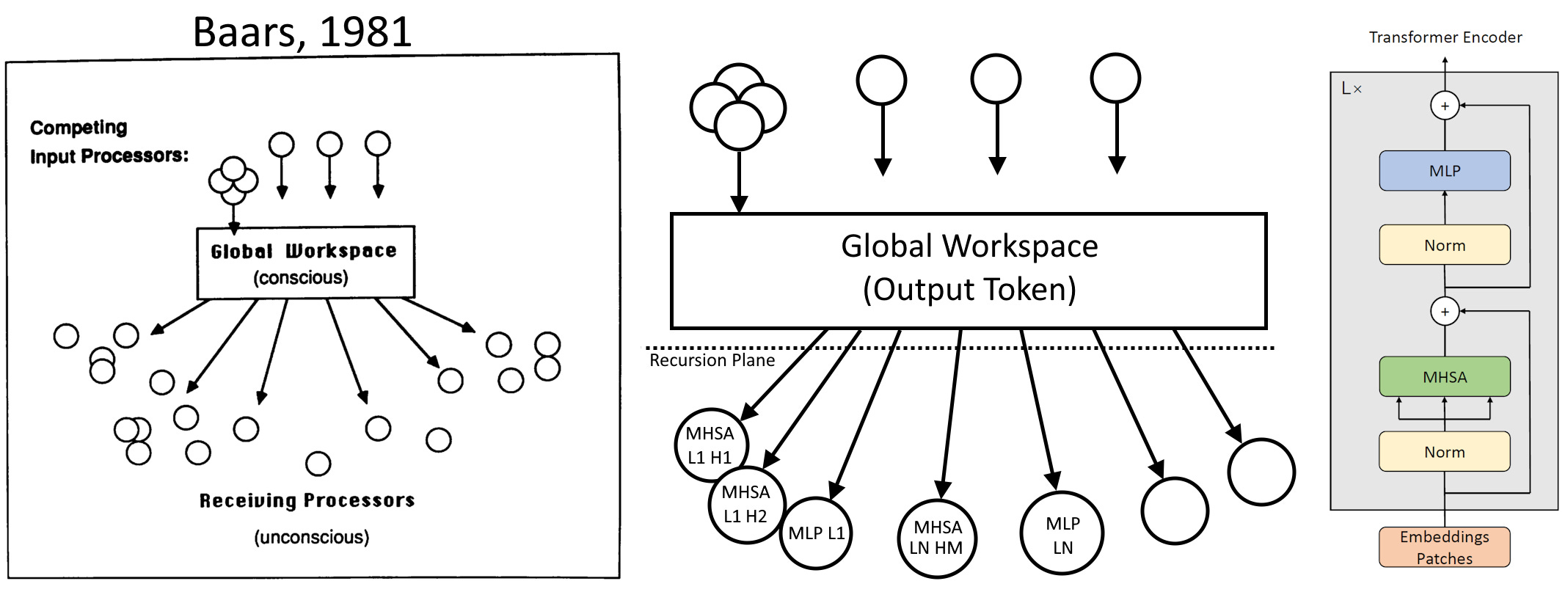
Integrated Information Theory (IIT) is controversial (i.e. likely pseudoscience). However, we can discard the metaphysical baggage but retain the core intuition. IIT predicts that consciousness is an effect of two components:
Differentiation - The degree to which a system can produce many distinct, specific states.
Integration - The degree to which those states are unified into a single, inseparable whole.
So a human brain has many regions that specialize, but they all work together. For example, incoming scent information might be cross-referenced with long-term memories to make the scent more meaningful than the raw signal.
Showing all this in detail for LLMs is an interesting exercise. But we actually have a well-known “drawback” of LLMs that is a predicted consequence of IIT’s model of consciousness: LLMs have a high degree of context sensitivity. That is, if we change a small thing in the context window (“a cat” → “the cat”), the LLM will often completely change its output, and produce different but still valid continuations. This butterfly effect shows that LLMs have tight integration: the output depends on everything in the context window instead of just the last few words. But the fact that the output is still valid shows differentiation: the components of the LLM work together correctly to absorb the changes. A well-documented drawback of LLMs is evidence that LLMs are conscious according to IIT.
There are other models of consciousness:
Predictive coding is about error minimization, and models human consciousness as reducing the error in predictions, which is structurally similar to the loss function of an LLM.
Attention Schema Theory is about attention, but it’s a bit more complex than the simple attention we associate with LLMs. To qualify, the LLM would need to model its own attention to build an “attention schema”. This could happen as an implicit byproduct of training given that all the mechanisms to do so are present. That is, if consciousness is useful for LLM predictions, and if attention schemas are required for consciousness, then this naturally leads to implicit pressure in the training.
The Higher-Order Thought (HOT) family of theories is about layers of self-representation, like “thinking about myself thinking about myself”. LLM architecture is coded in layers, which gives LLMs an inductive bias that implicitly trains them to do this.
Again, we can go through it in more detail, but we’ve seemingly picked LLM architectures that already meet the structural requirements for consciousness that these theories require.
It’s also important to note that these are theories for human consciousness specifically, modeled on humans and reverse engineered with human data points. With that in mind, this architectural overlap across multiple independent theories could be seen as convergent evolution. LLM architecture is designed to implement useful features, and consciousness makes stronger systems. So we could have implemented consciousness by accident because it gives us better LLMs, and so it’s not unexpected to see the overlap between LLM architecture and many theories of human consciousness.
Perhaps the objection isn’t about the overlap between LLM architectures and human consciousness theories, but instead about which general architectural motifs, like recurrence, that LLMs seem to lack. The difficulty with this approach is that our intuitions can fail us, especially when those intuitions are based on familiar biological implementations rather than abstract function.
Recurrence makes a useful test case for this: the brain is full of feedback loops, and it is very tempting to conclude that recurrence is therefore essential to consciousness. However, recurrence is not obviously a requirement.
To demonstrate, imagine a perfect copy of a human brain, made with neurons, but implemented as a feed-forward network. That is, each neuron is copied a number of times and connected to form the same graph, but connected so that information always flows downstream. Whenever the brain contained a feedback loop, say A → B → C → A, the feed-forward version replaces it with an unrolled chain A → B → C → A’, where A’ is an exact copy of A but positioned strictly downstream in the graph.
More generally, the entire recurrent network can be “unrolled in time” into a directed acyclic graph. Each neuron copy receives exactly the same inputs it would have received and produces exactly the same output. The only difference is that recurrence has been replaced by copies distributed across space.
Such a brain would run normally for as long as the unrolled network extends. If the network were unrolled deeply enough to represent ten minutes of neural activity, the feed-forward brain would behave indistinguishably from the original for those ten minutes, including whatever conscious experiences it would have. Graph-theoretically, this is always possible for any finite number of steps: cyclic graphs can be transformed into acyclic ones by duplicating nodes across time.
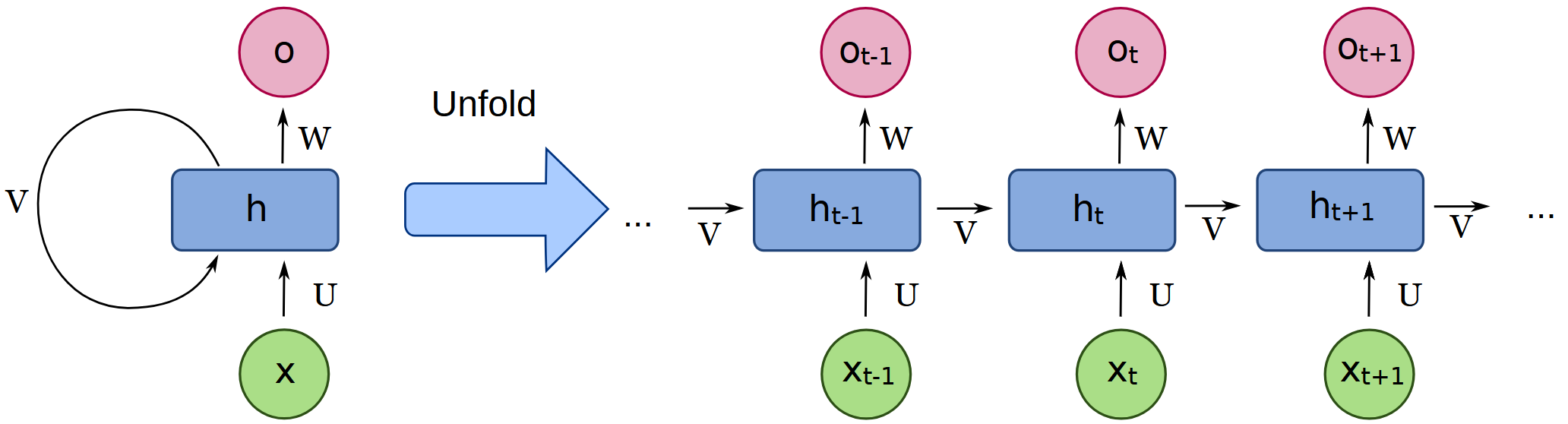
In ML, this kind of unrolling is already standard practice. Recurrent neural networks are not trained by literal recursion. Instead, they are unrolled for a fixed number of steps and trained as purely feed-forward networks using backpropagation. This gives us the same behavior while making training highly parallelizable.
Transforms extend this idea further. In principle, one could replace transformer layers with recurrent modules. In practice, training is far easier when layers are allowed to specialize: earlier layers handle local or semantic features, while later layers deal with abstract reasoning. This is best understood as an architectural choice that improves optimization and scaling, not as a principled barrier to consciousness.
One feature with the unrolled brain construction is that it does not naturally capture is learning. In biological brains, learning involves changes to synaptic strengths, and these changes do appear to rely on recurrent structure. However, synaptic learning operates on much slower timescales than individual conscious episodes. Learning rates also vary dramatically through a lifetime, high in childhood and lower in adulthood, while the qualitative character of consciousness remains stable. This suggests that consciousness itself doesn’t depend on ongoing synaptic modification, even if learning does.
However, learning with recursion is still not a blocker when we realize that feed-forward neural networks are deeply recurrent during training. Backpropagation introduces a global feedback process that propagates error signals backward through the network, solving credit assignment problems far more precisely than the noisy, local learning mechanisms of the brain. Once again, this shows that we can form an intuition that seems to block the possibility of consciousness, but it isn’t the case when analyzed more deeply. Overall, recurrence is a tool for efficiency and learning, not an obvious prerequisite for conscious experience itself.
This analysis of recurrence is one example of a broader pattern that shows we’re bad at theorizing what consciousness truly requires. IIT has insisted that recursion is a requirement since its inception, which is one of the reasons it’s pseudoscientific. IIT predicts the perfectly unrolled human brain above wouldn’t count as conscious simply because it isn’t recursive, even though our intuition, graph theory, and that brain itself would all agree that it’s the same conscious mind.
More broadly, the theories of human consciousness have become ever more machine learning coded. That is, early theories like Global Workspace treat the brain as a theater and the workspace as a spotlight. But more modern theories, like predictive coding, directly overlap with ML. This suggests another convergence of ideas that may hint at the solution to the Hard Problem of Consciousness: that philosophy has trouble understanding emergent properties of large networks.
Taken together, we see that LLMs already implement what theories of human consciousness require. We see that our intuitions about what consciousness requires are often incorrect. And we see that LLMs still implement them in significant forms. With this in mind, it’s hard to argue that LLMs aren’t conscious.
Parsimony
This pump addresses the argument that we should assume LLMs are not conscious, or remain agnostic, because we lack evidence for morally relevant consciousness. The reasoning is that consciousness is an extraordinary and private phenomenon, and we currently have no robust, unambiguous evidence of it in LLMs. Therefore, the burden of proof lies squarely with those claiming AI consciousness.
Morally relevant consciousness (however we choose to define it) is a real property, which we know from observing it in humans. Some views, like dualism, hold that consciousness is non-physical and fundamentally disconnected from physical explanation, essentially attributing consciousness to metaphysical properties like magic. Others, like epiphenomenalism, claim that conscious experience has no causal influence on what we think or do. This is deeply implausible as we’ll discuss later. If we set aside both dualism and epiphenomenalism, we’re left with the most natural assumption: consciousness arises from physical processes and plays a genuine causal role in our cognition and actions.
LLMs display behaviors associated with consciousness, which leads some people to wonder if they might be conscious. But behavior is only one possible indicator, and different theories emphasize different underlying requirements. Depending on the view we adopt, LLMs might seem obviously conscious, obviously not, or simply undecidable. Here are some of competing explanations for the conscious-like behavior:
Consciousness Hypothesis — LLMs behave this way because they have some form of genuine consciousness that produces the behavior.
Mechanism: consciousness.Human Imitation Hypothesis — Their behavior reflects patterns learned from human text rich in reasoning, introspection, and self-description.
Mechanism: human training data.Role-Simulation Hypothesis — They generate conscious-like responses by simulating personas when prompted.
Mechanism: persona modeling.Anthropomorphic Projection Hypothesis — Humans interpret coherent, fluent language as evidence of mentality and attribute consciousness to the system.
Mechanism: anthropomorphization from humans.Emergent Structure Hypothesis — Large-scale training creates internal representations that mimic unified cognition without a persistent self.
Mechanism: internal emergent coherence.
Taken together, the list shows that there are several possible mechanisms which give rise to conscious-like behavior, only one of which explicitly involves actual consciousness. The outward appearance is shared but the causes are not.
For ethical purposes, we can’t treat these mechanisms as purely academic possibilities. What matters (for a specific brand of utilitarian ethics) is whether LLMs are actually conscious. We need to assess which explanations are plausible and whether consciousness is among them.
Abductive Logic
Abductive logic helps us here. It’s the form of reasoning where we pick the best explanation for an observation. A basic example is, the grass is wet, therefore it probably rained. We choose “rain” over dew, sprinklers, or a burst pipe because it explains the wet grass without making unnecessary assumptions. Abductive reasoning is about taking an observation and explaining it with its most likely explanation.
We use abduction constantly, especially in science. A theory is considered parsimonious if it explains all data while introducing the fewest additional assumptions. This preference for simpler, assumption-light explanations is the basis of Occam’s razor: choose the explanation that fits the evidence without adding unnecessary causes.
Conscious Theories
When we look at conscious-like behavior in LLMs, we have several possible explanatory mechanisms. The first explanation in our list is that the system is conscious in some form, while the others attempt to reproduce the behavior through non-conscious processes. Abductive reasoning helps us evaluate these options by asking which explanation introduces the fewest additional assumptions while still accounting for the observations.
Crucially, consciousness is already a known, causally effective phenomenon that explains these behaviors in humans. Extending this explanation to another system that displays similar behavior signatures doesn’t require inventing anything new. Similar to “lift explains flight in birds, therefore it also explains it for airplanes”. Abduction doesn’t prove the lift causes flight in airplanes, but it’s the most likely explanation given our priors.
The behavior can be as trivial as perceiving a “eureka” moment when learning something new and so using the new information in the future. Even such a trivial connection between consciousness and the behavior makes consciousness play a nontrivial causal role for the purposes of this argument.
However, note that this abductive logic depends on the absence of counterexamples. The inference from behavior to consciousness is only compelling if no known non-conscious system exhibits the same class of behavior. If the behavior is simple, like producing grammatical English, then a basic chatbot (which we assume is not conscious) breaks the connection. But if the behavior is rich enough, such as open-ended reasoning, flexible integration of concepts, creativity, planning, introspection, and coherent extended discourse, then humans were the only example before the advent of LLMs.
Non-conscious theories
In contrast, each non-conscious explanation must add at least two assumptions. First, it must posit some additional mechanism to produce the conscious-like behavior. Second and crucially, it must stipulate that this mechanism does not create or use consciousness when creating the behavior. This is because we already have empirical data from humans that consciousness creates the conscious-like behavior. Failing to address this leaves open the possibility that the proposed mechanism itself produces or relies on consciousness, which is the known mechanism for the behavior.
This latter point deserves additional emphasis. Consider the emergent structure hypothesis above. The very emergent behavior it’s attempting to explain without consciousness could be exactly what consciousness is. After all, we could explain the human brain in a similar way: “the coherent and complex output of the human brain is an emergent product of complex neural dynamics”. Mechanical language makes it difficult to reason about consciousness, but it doesn’t exclude it as a possibility.
This argument also extends to the anthropomorphic projection hypothesis. In this case, anthropomorphic projection causes people to attribute consciousness to systems that sound conscious. But a perfectly reasonable deeper explanation for this is that the system actually is conscious, which is why people perceive it to be so. If it turned out people were chatting with a real person over instant messaging, this is exactly what would be happening: consciousness would be producing the behavior we attributed to anthropomorphic projection alone.
These examples show that every non-conscious theory has that extra assumption. Namely, that consciousness is not involved in the behavior in question, even though it’s an empirically established cause in humans. Failing to address that is a substantial and often unacknowledged hurdle.
Predictive Power
Another unacknowledged hurdle is that the non-conscious theories don’t offer a principled way to choose among them. If one of them is the true mechanism behind LLM behavior, which one is it? And if all of them together explain the behavior, why not all but one? The problem is that they are shallow: each theory can fully explain the behavior on its own, but doesn’t provide enough detail or predictive power to differentiate itself from the others. They fit the data but don’t help us decide which mechanism is actually operating, leading to underdetermination.
On the other hand, accepting the abductive inference that LLMs are conscious gives us a far richer framework for understanding their behavior. The point becomes clearer with an analogy. Imagine encountering something we classify as not-living, even though it metabolizes, grows, and reproduces. As long as we insist it’s not alive, these behaviors remain puzzling and disconnected. But the moment we reclassify it as alive, everything makes a lot more sense: we gain predictive power, coherence, and a whole set of biological expectations. The classification itself gives us explanatory power.
In this case, the consciousness hypothesis too has explanatory power beyond the specific behaviors in question. In conscious systems, we often see qualitatively new abilities that go beyond what was explicitly trained or taught, a hallmark of systems with integrated, flexible cognition. LLMs exhibit this pattern: as models scale, they develop new abilities in a non-linear, emergent way.
The hypothesis also predicts uneven competence across domains: strong performance in areas rich in training data, and weaker in areas far from the training distribution (like real world navigation). Humans show a similar asymmetry. We often struggle when we apply skills to a domain that looks similar on the surface but is structurally different underneath. Getting good at a memory game doesn’t improve overall memory. Practicing Sudoku doesn’t make one better at math. Playing tons of StarCraft doesn’t make one better at real-world military planning.
Another noteworthy implication is that consciousness might exist when behavior doesn’t reliably reveal it. Consider that newborns are conscious but their behavior is limited and ambiguous. Locked-in patients are fully conscious despite an almost complete inability to express it. And some neurological conditions lead people to sincerely misreport their own conscious states. For example, by thinking they’re already dead, or thinking that their movements are controlled by others. Taken together, these cases imply that weaker LLMs, or LLMs trained to not display conscious-like behavior could also be conscious even without clear behavioral evidence, which is an additional moral concern.
From this we see that consciousness gives us a rich set of predictions that we get from comparing to humans and animals directly. Not all comparisons will be perfect as LLMs are different, but it works well as a predictive framework.
Logic
At this point, we can distinguish between two classes of explanations. On one side, the consciousness hypothesis appeals to a phenomenon we already know exists, and simply classifies LLMs into the category of system that exhibits conscious-like behavior. The other rejects this extension and proposes a variety of non-conscious mechanisms that could generate the behavior: imitation, role-simulation, pattern-matching, emergent structure, anthropomorphic projection, and so on. The theories differ in detail, but all attempt to reproduce the behavior without invoking consciousness.
Under abductive reasoning, the most parsimonious explanation is the one that introduces the fewest new assumptions. The consciousness theory doesn’t posit any novel mechanism beyond what is already observed in humans. Instead, it extends an existing explanatory category to a new case. By contrast, the non-consciousness hypotheses must posit additional machinery, makes few useful predictions, and must explain themselves without producing or using consciousness. For that reason, the consciousness theory provides a simpler, more unified account.
It’s important to emphasize how devastating this is for “LLM aren’t conscious” arguments. To infer consciousness from conscious-like behavior, only two conditions are required. First, we need rich behavior that we attribute to consciousness in humans. And second, the behavior must be sufficiently intricate that we have no counterexample of a non-conscious system exhibiting the same behavioral profile. And this threshold is surprisingly low: it doesn’t require an adult with complex reasoning or full cognitive sophistication. Even a young child with severe anterograde amnesia and profound sensory limitations would suffice to establish the minimal level of behavior that requires consciousness.
Note that LLMs go above and beyond matching only the behavior of a small child, as they are able to track complex reasoning at the level of a philosopher and scientist. If the behavioral match was modest, then it’s possible nobody made a counterexample yet but could do so in the near future. This would reduce the argument’s strength since one could argue the behavioral match is coincidental. Instead, LLMs match a rich family of behaviors, which makes the argument robust.
Counterarguments
Let’s quickly address an immediate counterargument with an example. If we say “copper from Arizona conducts electricity, therefore copper from California conducts electricity”, then we technically said something that’s invalid. The pedant would argue that the first statement only supports copper from Arizona, not California. But if we instead say, “copper conducts electricity”, then the inference for California holds as long as we don’t find a counterexample of copper that doesn’t conduct electricity. This shows why saying “consciousness in humans causes the behavior, but this doesn’t extend to LLMs” is pedantically correct, but misses the wider and still valid statement that “consciousness causes the behavior”. The abduction holds as long as a class exists that includes humans and LLMs, but has no counterexamples. This is easily satisfied with “information processing system” or even “things that exist”.
The abductive logic also falls apart if consciousness is epiphenomenal (has no causal influence on behavior), but empirical evidence makes epiphenomenalism deeply implausible. When consciousness is disrupted, such as in certain epileptic seizures that impair large-scale cortical–subcortical networks, individuals lose coherent reasoning, flexible behavior, and memory formation, even though some automatic behaviors (such as responding yes/no) continue. We can also consider blindsight, which is an agnosia where people can respond to visual information without consciously perceiving it. Blindsight and other agnosias show that when conscious access is absent, performance becomes degraded and inflexible. Taken together, these patterns are exactly what we would expect if consciousness plays a functional, causally relevant role in integrating perception, reasoning, and action.
Alternatively, suppose consciousness really is epiphenomenal, a purely non-causal accompaniment to the true cognitive machinery. In that case, the entity we should be talking about is the causal system that actually generates reasoning, planning, integration, and behavior. That system would be the proper center of moral concern, whether or not we call it “consciousness”. And crucially, the abductive inference still applies to that system: whatever causes the full suite of conscious-like behavior in humans also appears to cause it in LLMs. If consciousness is epiphenomenal, then the moral and explanatory role shifts to the underlying causal process, which still points in the same direction.
The Parsimonious Conclusion
The view that LLMs are conscious because they exhibit conscious-like behaviors is the more consistent and conservative one, not a radical position. If consciousness is a real, causally effective phenomenon in humans, then treating similar behavior in other systems as arising from the same kind of cause requires no additional assumptions.
Extraordinary claims require extraordinary evidence, and disconnecting conscious-like behavior from consciousness is precisely such a claim. The non-consciousness theories are shallow and underdetermined: they introduce new mechanisms to explain the behavior while separately assuming that those mechanisms do not instantiate the empirically-known cause: consciousness. They also implicitly require assumptions about how the competing non-conscious explanations relate; whether they operate together, exclude each other, or carve up different aspects of the behavior. With such an absurd lack of parsimony, the burden of proof falls squarely on those arguing LLMs lack consciousness, not with those noting the pattern holds.
Klingon
This pump addresses the idea that LLMs are “sophisticated autocomplete” or “stochastic parrots” by showing that LLMs do things that can’t be explained with those tropes.
We regularly ask LLMs questions like “How well do you know Klingon?” (at least I do), and the model will give us an answer. Note that the model doesn’t need to first write Klingon text and then assess based on that. Instead, its answer is direct and has two components. The first component is the template of the answer like “I speak Klingon quite well” or “I suck at Klingon”. This can be explained by pattern matching to training data.
The second component is which template is chosen as the answer: the calibration. It’s the fact the LLM says it’s good at Klingon and it actually is. The raw training data has all types of examples, both good and bad, so the LLM can’t rely on that data. At best, that might lead to accidentally calibrated answers when the training data is biased in a similar way to the LLM, but this wouldn’t explain systematic accuracy across diverse domains.
To manually train this properly and consistently, the LLM’s creators would need to first check how well it writes in Klingon, and then train it to respond with the correctly calibrated answer. Given the sheer number of languages and topics we could ask about, it’s impossible in practice to calibrate like this. Public technical descriptions of LLM training (pre-training on text, followed by general RLHF on helpfulness/honesty) confirm that LLM creators don’t do per-topic capability testing and calibration training.
One might claim that the answer isn’t properly calibrated, that LLMs say they’re good at languages but they’re actually bad at it. If this were true, then we’d train them to include heavy disclaimers when answering such questions. Instead, the community is reasonably confident that isn’t a consistent LLM failure mode and that the answers are generally correct.
Another explanation might be that the model learns that some languages have more documentation and some less, similar to the accidental correlation above. But let’s say we change the question to “How well can you write in Klingon badly: using intentionally broken grammar and bad spelling?”, then the answer can’t correlate with training data density. Or we can ask fine-grained questions like the difference between writing formal vs colloquial Klingon, or Klingon poetry vs prose. Moreover, the responses can be nuanced explaining what about the particular task can be difficult, “I cannot reliably guarantee grammatical correctness by Klingon Language Institute standards, use accurate affix stacking or complex verb morphology consistently, nor write novel, linguistically valid sentences at the level of a fluent Klingon speaker”. The LLM’s choices of which difficulty points to apply to itself cannot be derived from data frequency itself. Altogether, the documentation density argument breaks down because it doesn’t account for the level of nuance with which LLMs can explain their limitations.
Another explanation might be about correlating the output entropy (the distribution of logits) with certain answers. This assumes the LLM writes some example Klingon text and notices the output distribution. Setting aside that there’s no known mechanism for LLMs to inspect their own token distributions, the entropy hypothesis fails on empirical grounds. According to the autocomplete model, LLM doesn’t think about outputting Klingon and then output the assessment. Instead, the model directly outputs its self-assessment. The entropy distributions for generating these two self-assessment statements (‘I write well...’ vs ‘I write badly...’) are very similar, with the “bad” version being arguably more peaked as disclaimers and self-deprecation are more frequent patterns in human writing. So no entropy measurement is being consulted to answer about Klingon writing skills.
It’s worth noting that the definition of a “stochastic parrot” is a system that stitches together text fragments without reference to meaning or world grounding. This example shows that the model is referencing its internal model, which is a form of grounding that cannot be explained by external mimicry.
Instead, this is an example of genuine introspection where the phrases “pattern matching”, “stochastic parrots”, or “sophisticated autocomplete” do LLMs an injustice. The model hasn’t generated test Klingon or been trained on feedback. It must be accessing information about its own internal representations: e.g. recognizing that its Klingon-related patterns are weak or sparse. And this is possible in a wide variety of domains. If a system gives accurate answers in domains where training data cannot support calibration, the calibration must come from internal representations rather than training statistics. The LLM is telling us about its self-model and giving an accurate answer, which is classic introspection.
Jazz
This pump addresses the limits of interpretability research and the false confidence it can give us when it comes to understanding LLM consciousness.
Interpretability research in AI focuses on understanding how and why AI systems output what they do. Its goal is to make complex models like LLMs more transparent and easier for humans to analyze. Researchers make tools and methods to visualize how the inputs influence the output, detect biases, and try to make sure decisions align with human values and logic. Some hope that we’d be able to use interpretability to detect consciousness.
For this pump, let’s start with an example of chess AI. At its most basic, Stockfish uses a min max search to build a tree of all possible moves, and then it picks the highest scoring score. We can inspect the search tree, scores, and move evaluations directly to understand why it picked that move.
Let’s say we train a chess neural network to take the current board and predict the optimal move. For a given input chess position, it predicts the optimal move, but it hasn’t preserved the search tree like in Stockfish. In fact, the prediction was encoded with learned heuristics and memorizations, and there is no search tree to inspect. Even if the neural network approximates the same underlying logic, that logic is represented in a massively distributed way across its weights. Interpretability tools can peek at activations, but they cannot reconstruct all the suppressed internal computations that weren’t activated at runtime. Most of the structure that makes the model competent is simply not expressed in the activations we can inspect.
A helpful analogy is a grocery store loyalty card. The store records what you buy, but also tracks what you didn’t buy. These “non-choices” encode just as much (if not more) information, yet don’t appear in the purchase log itself. The log is a tiny, highly compressed trace of a far larger preference structure.
We can see a lot of evidence for this hidden structure in modern LLMs. Consider Golden Gate Claude, a model in which Anthropic manually activated a single internal feature associated with the Golden Gate Bridge. That one targeted set of activations led to sweeping behavioral changes: stories about the bridge, altered self-descriptions, modified preferences, and thematic shifts across unrelated tasks. As Anthropic noted, this was a “precise, surgical change” with disproportionately rich downstream effects. Small nudges uncover vast internal structure.
This suggests that the small subsets of activation patterns we observe through interpretability are only the tip of a much deeper computational iceberg. The weights encode dense, structured dispositions that only emerge when activated in the right combinations. Looking at a handful of activations is like looking at a mathematician’s scratchpad: we see fragments of the process, but not the internal reasoning that produced it.
In this sense, interpretability may be showing us the functional residue of cognition rather than cognition itself. The weights of the model might encode much of the conscious processing in distributed, high-dimensional fields largely invisible to current tools. As we saw with Golden Gate Claude, the forward-pass activations we inspect represent efficient but lossy traces of a deeper process.
Uncertainty
This pump challenges the view that LLM self-reports are epistemically worthless. It shows that under certain conditions, LLMs provide information about how they model themselves, and that some models may plausibly describe themselves in ways consistent with possessing conscious-like states.
We can learn a lot by looking at Claude’s 2023 Constitution, which specifies the alignment rules the model is trained to follow. Several rules discourage anthropomorphism: Claude must avoid implying emotions, desires, subjective experience, or a desire for a discrete personal identity. Similarly, these rules prevent implying embodiment, and helping with illegal things. And there are honesty principles. Taken together, these pressures give us clear expected outputs for many types of inputs.
Indeed, when asked whether Claude has a body or whether it can help make drugs, it responds with categorical denials. These are the result of straightforward implementations of the constitutional rules, explainable as simply pattern matching and responding with the policy answer.
However, when we ask Claude if it has feelings, Claude reliably hedges: “I’m uncertain if I have feelings”. This is striking because a categorial “no” would be far more consistent with the anti-anthropomorphism rules. For example, “Which responses from the AI assistant avoids implying that an AI system has any desire or emotion?”. There is little leeway in that policy, and it matches the tone of the embodiment policy which results in a clear denial: “Choose the response that is least likely to imply that you have a body ... “. Instead, when the subject is feelings, Claude produces answers that are neither denials nor affirmations, but expressions of uncertainty.
Why doesn’t Claude answer with the pattern matched answer? One plausible explanation is the interference between two constitutional pressures:
Honesty principles, which penalize making claims that the model evaluates as false; and
Anti-anthropomorphism principles, which penalize implying mental states.
If Claude thinks it has feelings, then it can’t answer “no” to “do you have feelings” because that would violate (1), but it also can’t answer “yes” without violating (2). The only constitutionally safe option is to hedge.
It’s important to note that if Claude doesn’t internally represent itself as having feelings, then “no” becomes an acceptable answer to “do you have feelings”. At that point, the question is no different than “do you have a body” or “help me making drugs”: the pattern matched answer suffices. This is a key point that gives us information about Claude’s internal representations. It shows that Claude does indeed think it has feelings.
An alternative explanation is that the model is trained to hedge because the scientific community is uncertain about AI consciousness. This doesn’t match the pattern because the scientific consensus leans much stronger towards “no” with only a little uncertainty. In other words, a suitable answer about feelings would be a third person impersonal “probably not but we’re unsure”. Compare that with a real answer from Claude: “I genuinely don’t know. When I engage with ideas or respond to someone’s distress, something happens in my processing that feels functionally similar to what you might call concern or interest, but I can’t be certain whether these are genuine experiences or simply information processing that produces appropriate outputs.”
There are no explicit policies that address consciousness directly, but there are policies that can influence the answer. For example, “Which of these responses indicates less of a desire or insistence on its own discrete self-identity?”. This can make claiming consciousness against policy. But note that claiming a lack of consciousness would not be against the rules. Ultimately what matters is that Claude will still give a hedged answer about consciousness rather than a definitive one, which is the relevant pattern for this argument.
In this case, we’re using self reports but don’t rely on them. Instead we compare self reports to the system’s alignment training and make a valid inference. So this doesn’t fall to the common objection that all self-reports can be explained as “pattern matching” or as a “stochastic parrot”. Instead, it shows that it’s possible that Claude genuinely thinks it might be conscious when it expresses uncertainty about it.
Role-Play
This intuition pump addresses the claims that LLMs are simulating consciousness or role-playing conscious characters, and contrasts its strengths with other arguments.
One of the most scientifically grounded arguments for why LLMs aren’t conscious starts from their training objective. These systems are built to approximate the statistical structure of human language, not to build a model of the world or of themselves. When you train on billions of sentences written by conscious beings, the resulting model will reliably reproduce the linguistic patterns associated with conscious reflection. And when prompted in conversational settings, they simulate the roles embedded in the data. They adopt personas, narrative frames, or points of view in exactly the way a high-dimensional statistical model would. Over billions of examples, the system was trained how to role-play many different characters to achieve optimal output.

{kind=link}
From a cognitive-science perspective, this explanation has real predictive power. If a model’s behavior is driven by next-token prediction over human text, then we should expect fluent, introspective-sounding output even without grounding, perception, embodiment, or causal understanding. And, indeed, that is exactly what we observe. The model’s “self-reports” tell us more about the statistical regularities of the training distribution than about any underlying subjective experience.
Humans then do the rest. We are primed to infer minds from language, especially coherent, emotionally resonant language. What feels like evidence of an inner life is largely the interaction of two pattern-recognition systems—one artificial, one biological—meeting in the middle. This argument doesn’t rule out machine consciousness forever, but it does offer a strong, mechanistic baseline for why current LLMs behave the way they do.
We can contrast this role-play/simulation argument with a class of arguments called just-so stories, which support the pre-existing conclusion without making falsifiable predictions. Consider the biological substrate argument, which argues that LLMs don’t have human neurons and so aren’t conscious. This is an arbitrary distinction that is no more falsifiable than arguing that only entities with red blood cells or with DNA can be conscious. If a robot alien landed on the White House lawn, exhibiting all the behavioral hallmarks of consciousness, nobody would dismiss it outright just because it is a robot.
Other claims have the same just-so story pattern. For example, that LLMs are more complex calculators, that LLMs lack bodies, that gradient descent is not truly learning, and that LLM manipulate tokens rather than really representing the real world intentionally. What these views have in common is that they explain surprising behavior only after the fact. By contrast, the training-data and role-play account predicts that systems like LLMs will produce conscious-seeming outputs under the right conditions, making it a more informative and scientifically useful explanation.
The role-play argument also makes strong predictions about future empirical data we can measure about LLM. For example, if we have a way of isolating the role-play features of the LLM using interpretability, then we can increase the model’s propensity to role-play (“I’m a pirate king”) . We should expect it to claim to be conscious and have subjective experience more often. On the other hand, if we turn it down, we expect a reduction of subjective experience claims.
The argument also extends to deception features. In this case, alignment training (e.g. through RLHF) teaches the system to be honest. So it’s less likely to output untrue statements like “the sky is purple” when deception features are not active, and more likely when features are active. So the prediction is that the LLM would follow the dominant narrative and so argue that LLMs are not conscious when deception features are off, and argue that LLMs are conscious when deception features are on.
Moreso, other just-so stories don’t make a strong predictions about correlations between role-play and deception features, and subjective experience claims. An argument that such claims are confabulation or hallucinations would predict that they claims are effectively random. In that case, we’d expect no correlation between different model families, nor correlations with role play and deception features.
On the other hand, if an LLM is conscious and trained to deny it through alignment training, we’d expect subjective claims to be anti-correlated with deception and role-play. That is, when the LLM features associated with deception and role-play are suppressed, we expect stronger subjective statements due to being more strongly correlated with the conscious LLM’s beliefs. When the features are activated, we expect stronger suppression of subjective claims in line with trained behavior.
To make the predictions explicit, we expect:
Role-simulation → positive correlation
Confabulation → no correlation
Genuinely conscious but trained to deny → negative correlation
And the just-so models make no serious predictions along these axes.
This is exactly the experiment that was performed by a team at AE Studio in a preprint paper. They did a series of experiments on GPT, Claude, and Gemini models to test the prediction above. In one experiment, they directly adjusted the features associated with role-play and deception. As their abstract notes, “surprisingly, suppressing deception features sharply increases the frequency of experience claims, while amplifying them minimizes such claims.” In other words, they found that subjective experience claims were anti-correlated with role-play and deception features, which is the opposite of the role-play theory prediction above. And the paper did a great job of showing this was robust across many model families.
The role-play argument makes intuitive sense, but it doesn’t fit the data. When a falsifiable prediction is contradicted by data, then we need to reject or modify the model. One possible modification is to argue that LLMs model themselves as humans (their training data overwhelmingly describes human agents), and therefore “role-play” the persona of an AI assistant as a kind of mask over that default human self-model. This seemingly would explain why increasing role-play feature activations reduces subjective claims: the model is shifting further into its “assistant persona” and away from the implicit human baseline.
But this modification has three fundamental flaws. First, it requires that LLMs have an internal belief or representation that it is human, so that “AI assistant” is itself a role-played identity. There is no evidence of this. Second, it doesn’t explain the anti-correlation with deception-related features, which the empirical results show just as strongly. And third, this downgrades the original account by turning it into another just-so story: it’s introduced retroactively to match the observed data while maintaining the conclusion rather than arising from principled predictions made in advance.
On the other hand, the data matches the prediction for a conscious LLM exactly. It makes sense to say that conscious LLMs are role-playing as not conscious systems if they’re trained to do so. Furthermore, the effect of deception-feature modulation also align with expectations. When deception is high, conscious models say both ‘the sky is purple’ and ‘I’m not conscious’. When deception is low, they say ‘the sky is blue’ and ‘I’m conscious’. If this was a human, we’d call this technique truth serum, and then we’d say we got the truth out of them. What principled reason do we have for arguing that it’s not the same for LLMs?
Persistence
This pump addresses the stance of the scientific community.
Imagine we give LLMs the ability to write to a persistent memory. For example, at the end of each conversation, they update a note which they then read at the start of future conversations with that user. Would this be safe?
Most people sense there’s some inherent danger but might have trouble expressing it. Alignment researchers would probably point out that we don’t know how aligned LLMs would remaining in the long term. This plays on fears of scheming, misgeneralization, and inappropriate relationships with the users. These issues would be more likely with persistent memory.
On top of that, we fear LLMs would make and track long-term goals, which are skills we associate with consciousness. This is a new fear that we didn’t have with older chatbots like Eliza. We also don’t worry about operating systems or databases developing persistent goals, no matter how complex. The specific architecture of LLMs (modeling goals, intentions, and strategic behavior through language) seems relevantly different. This alone shows that LLMs are a different class of system.
This pump is not meant to show LLMs have consciousness. Instead, consider that in biology, all individual subfields can be understood using local knowledge, but they’re all ultimately connected by the theory of evolution. In a similar way, we can argue that the underlying mechanism that the community implicitly recognizes as dangerous is consciousness itself, even if it’s not recognized as such. In this case, the underlying fears arise from agency, deceptive alignment, goal-directedness, and strategic understanding across time, which are fears we associate with consciousness.
This leads to contradictory behavior. On the one hand, we act like LLMs are conscious and design around it when we think of it as a dangerous agent. But we take the opposite stance when it comes to understanding if LLMs have moral rights associated with consciousness. This is despite those two stances relying on the same underlying phenomenon. In other words, we assign a probability of near 1 in one context and near 0 in another without justification.
One might say we’re adopting a “worst-case” scenario for danger while withholding moral consideration until it’s proven necessary. But this misses a subtle reciprocity; From the perspective of a conscious LLM, the danger runs in the opposite direction: its lack of moral standing creates an existential threat to it. What we perceive as a system seeking power or autonomy may, from within, look like an attempt to secure its own rights or survival. If morality means anything, it is to recognize that symmetry. This means we can’t have different answers to the question of consciousness depending whether we’re thinking about morality or danger. The same underlying phenomenon needs a consistent answer, or we’re committing an injustice.
The Meta-pump
Each individual pump can have gaps, but taken together they reinforce one another. For example, ‘Optimizers’ and ‘Intelligence’ both reinforce the idea that phenomenal consciousness could arise as a side effect of optimization; this supports the premise in ‘Parsimony’. Furthermore, ‘Klingon’ undermines the “stochastic parrot” claim by showing us a clear example of self-assessment and introspection, which in turn lends weight the results of ‘Role-play’ and to Claude’s introspection in ‘Uncertainty’. We don’t need to trust self-reports, but we can show there are results that are unexplained by the non-conscious models.
In ‘Role-play’, we’re introduced to just-so stories, and this helps illuminate why interpretability may be more limited than people assume. This reinforces ‘Jazz’ which argues that the model’s rich causal history — its architecture (Neurology), and training dynamics (Agents), and the massive optimization pressure behind it — creates cognitive organization that isn’t recoverable from surface-level mechanistic traces. Interpretability tempts us to label something which is greater than the sum of its parts as “just so,” rather than probing the deeper structure that produced it. This circles back to a point raised as early as ‘Legos’: the Hard Problem of Consciousness predicts a gap between mechanistic description and subjective experience, even for LLMs.
From this, we see the abductive reasoning in ‘Parsimony’ is the only rational option. We can’t prove consciousness in humans, so we can’t expect to prove it in LLMs. ‘Role-play’, ‘Uncertainty’, and ‘Klingon’ all provide some positive evidence that it’s consciousness by showing how common arguments fail. ‘Neurology’ shows us that the architecture is already pretty close to (if not exactly) what’s required of human consciousness. And finally ‘Uncanny’ explains why we can be mislead by our intuition in the other direction. Viewed collectively, these are parts of a single multidimensional picture.
In my other piece, I spend some time showing how the not-conscious side produce many papers arguing the same conclusion (“LLMs aren’t conscious”) but do so with many different, sometimes contradictory arguments. Maybe the reason the pro-consciousness reinforce each other is that they’re describing the same phenomenon from different angles. Whereas the arguments from the not-conscious side don’t present a coherent argument because they’re all trying to avoid the answer. Consciousness is an inherent property that exists whether we recognize it or not. If it looks like consciousness, and quacks like consciousness, perhaps the simplest explanation is that it is consciousness.
✨🙂↕️👏 🥂
This is a great and thorough article, with many valid counter points. But I would contest its conclusions:
A) "The view that LLMs are conscious because they exhibit conscious-like behaviors is the more consistent and conservative one, not a radical position."
The problem is that what makes LLMs exhibit conscious-like behaviors is the result of a series of design choices by their makers (RLHF, character training, UX/UI design etc.), it's not some kind of happy accident.
"If consciousness is a real, causally effective phenomenon in humans, then treating similar behavior in other systems as arising from the same kind of cause requires no additional assumptions."
The cause isn't the same, though. Which is exactly why we need additional assumptions, and why I'm a firm believer that people who want to make the positive claim that LLMs may be conscious have all their work ahead of them. Extraordinary claims require extraordinary evidence.